Duplicate Content
Duplicate Content (deutsch: doppelter Inhalt) stellt das Gegenteil von einzigartigem Content dar. Es handelt sich daher um identische beziehungsweise kopierte Webinhalte, welche auf einer oder mehreren Websites zu finden sind. Suchmaschinen filtern duplizierte Inhalte heraus und entfernen sie aus den Top-Ergebnissen im Suchmaschinenindex, sodass die Website der Originalquelle im Ranking besser zu finden ist. Für die Suchmaschinenoptimierung stellt Duplicate Content daher eines der Hauptprobleme dar.

Inhaltsverzeichnis
- 1 Was ist Duplicate Content?
- 2 Interner und externer Duplicate Content
- 2.1 Beispiele für Quellen von internen Duplicate Content
- 2.2 www. und non-www Version einer Webseite
- 2.3 Mobile friendly URLs und Druck-Versionen
- 2.4 Paginierungen als Duplicate Content Falle
- 2.5 Beispiele für externen Duplicate Content
- 2.6 Übernahme von Herstellertexten im Shop
- 2.7 Pressemitteilungen als Falle
- 2.8 Content Diebstahl
- 3 Warum ist Duplicate Content negativ für SEO?
- 4 Duplicate Content erkennen
- 5 Vermeidung von identischen Inhalten
- 6 Quellen
Was ist Duplicate Content?
Bei Duplicate Content wird von ähnlichen oder identischen Inhalten auf einer oder mehreren Websites gesprochen. Grundsätzlich kann dies in jeglicher Form von Content, wie Beispielsweise Videos und Bildern vorkommen. Für SEO sind aber vor allem kopierte Textinhalte ein problematisch.
Google unterscheidet folgende Arten:
- identischer oder nahezu identischer Text
- Inhalte, die auf mehreren Domains, Subdomains bzw. URLs eingebaut sind
- Verwendung von Desktop, Mobile und druck-freundlichen URLs, CDN–Anbieter
- Pressemitteilungen, Tag-Seiten, gekaufter Content, gleiche Seitentitel und Descriptions
Texte, die in mehreren Sprachversionen existieren und Zitate sind keine Duplikate. Zitierungen sollten daher im Quelltext als solche kenntlich gemacht sein, damit Google sie als solche erkennt.
Angabe eines Zitates im Quellcode:
<blockquote>Dies ist ein Zitat – <cite>Dies ist der Name des zitierten</cite></blockquote>
Interner und externer Duplicate Content
Duplizierte Inhalte können unter der eigenen URL in Unterkategorien (intern) oder auf weiteren Webseiten (extern) auftauchen.
Für Google scheinen interne Dopplungen ein kleineres Problem als die externen Duplikate zu sein. Jedoch sollten auch interne Dopplungen vermieden werden.
Beispiele für Quellen von internen Duplicate Content
- Tag-Übersichtsseiten
- Filter-Übersichtsseiten
- interne Suchergebnisseiten
- Kategorie-Seiten
- Produkteinzelseiten, wenn sie unterschiedlichen Kategorien zugeordnet sind
- Beiträge, wenn sie unterschiedlichen Kategorien zugeordnet sind
- Pagination
www. und non-www Version einer Webseite
Falls sowohl unter www.ihrewebseite.de, als auch unter ihrewebseite.de eine Webseite zu erreichen ist und dort die gleichen Inhalte ausgeliefert werden, werden doppelte Inhalte produziert. Obwohl Content-Management-Systeme wie zum Beispiele WordPress dieses Problem bekämpfen, taucht es immer noch auf vielen Seiten auf. Die Webseite darf jedoch nur noch in einer Version ausgeliefert werden. Es hat sich allerdings bei den Nutzern etabliert, eine URL beginnend mit WWW in den Browser zu tippen.
Mobile friendly URLs und Druck-Versionen
Ein Problem, was in diesem Zusammenhang besonders häufig vorkommt, ist das Ausliefern der mobilen Inhalte unter einer gesonderten URL. Aus Sicht der Nutzer sauber gelöst, jedoch für Suchmaschinen sind es die gleichen Inhalte unter verschiedenen URLs.
Das gleiche Problem tritt auch bei Inhalten auf, welche speziell für Drucker aufbereitet worden sind. Oftmals werden nur Texte von Webseiten ausgegeben, ohne Bilder und weitere Formatierung in CSS.
Häufig werden diese Druckansichten dann unter gesonderten URLs ausgegeben. Diese URLs duplizieren auch wieder die bereits unter anderen Adressen vorhandenen Inhalte. Auch an dieser Stelle produziert die Webseite Duplicate Content.
Paginierungen als Duplicate Content Falle
Diesen Fehler finden tauchen regelmäßig in Onlineshops auf, hinweg über alle gängigen Shop-Systeme. Der versierte Shopbetreiber hat bereits die Kategorien seines Shops optimiert und maschinenauslesbare Inhalte geschaffen. Dies ist aus Sicht der Suchmaschinenoptimierung ein korrektes Vorgehen.
Kritisch wird es oftmals erst dann, wenn die Produkte einer Kategorie über mehrere Seiten aufgeteilt werden (Paginierung). Dies führt in vielen Shop-Systemen zu doppelten Inhalten.
Beispiele für externen Duplicate Content
- Übernahme von Hersteller-Artikel-Beschreibungen
- Content-Diebstahl
- Content-Scraping Content-Einspielung über RSS-Feeds
- Verbreitung von Pressemitteilungen
- Nutzung von Inhalten über Affiliate-Seiten
- Webseite die über verschiedene Hostnamen erreichbar sind
- Gleiche Inhalte auf verschiedenen firmeneigenen Domains
Übernahme von Herstellertexten im Shop
Die Übernahme von Produktbeschreibungen der Hersteller im eigenen Shop, ist ein einfacher Arbeitsschritt. Jedoch aus Sicht der Suchmaschinenoptimierung ein fataler Fehler. Die Suchmaschinen fordern, dass möglichst einzigartige Inhalte auf einer Webseite erscheinen und keine vorhandenen Inhalte übernommen werden.
Pressemitteilungen als Falle
Hinter Pressemitteilungen verstecken sich gleich mehrere Fallen. Zum einen werden Inhalte oftmals über hunderte Presseportale verteilt. Dies kann in den Augen von Google bereits als Spam und Manipulation der Suchergebnisse gewertet werden. Zum anderen entsteht ein Duplicate Content, wenn die Pressemitteilung auch noch auf der eigenen Seite publiziert wird.
Content Diebstahl
Es ist leider keine Seltenheit mehr, dass selbst erstellte Inhalte von der Konkurrenz kopiert werden und auf der eigenen Seite eingestellt werden. Auch dies ist für eine optimale Positionierung in den Suchmaschinen nicht förderlich. Daher sollte die Webseite regelmäßig mit Tools wie copyscape oder ähnlichen überwacht werden.
Warum ist Duplicate Content negativ für SEO?
Nach Aussagen von Google, möchte die Suchmaschine ihren Nutzern relevante und einzigartige Inhalte zur Verfügung stellen und Dopplungen im Index meiden. Vermutet Google einen Manipulationsversuch des Rankings durch das Duplizieren von Texten, rutscht die entsprechende Webseite im Ranking nach unten oder wird ganz aus dem Index entfernt.
Google arbeitet mit einem automatisierten Verfahren, mit dem Unique Content erkannt und Duplicate Content herausgefiltert wird. Dabei werden nicht nur ganze Texte betrachtet, sondern einzelne Textpassagen verglichen. Durch das Vergleichen einzelner Textpassagen, kann Google auch Texte, die durch das Umstellen von Sätzen oder das Einfügen von Füllwörtern abgewandelt worden, immer noch als Duplikat der Originalquelle identifizieren.
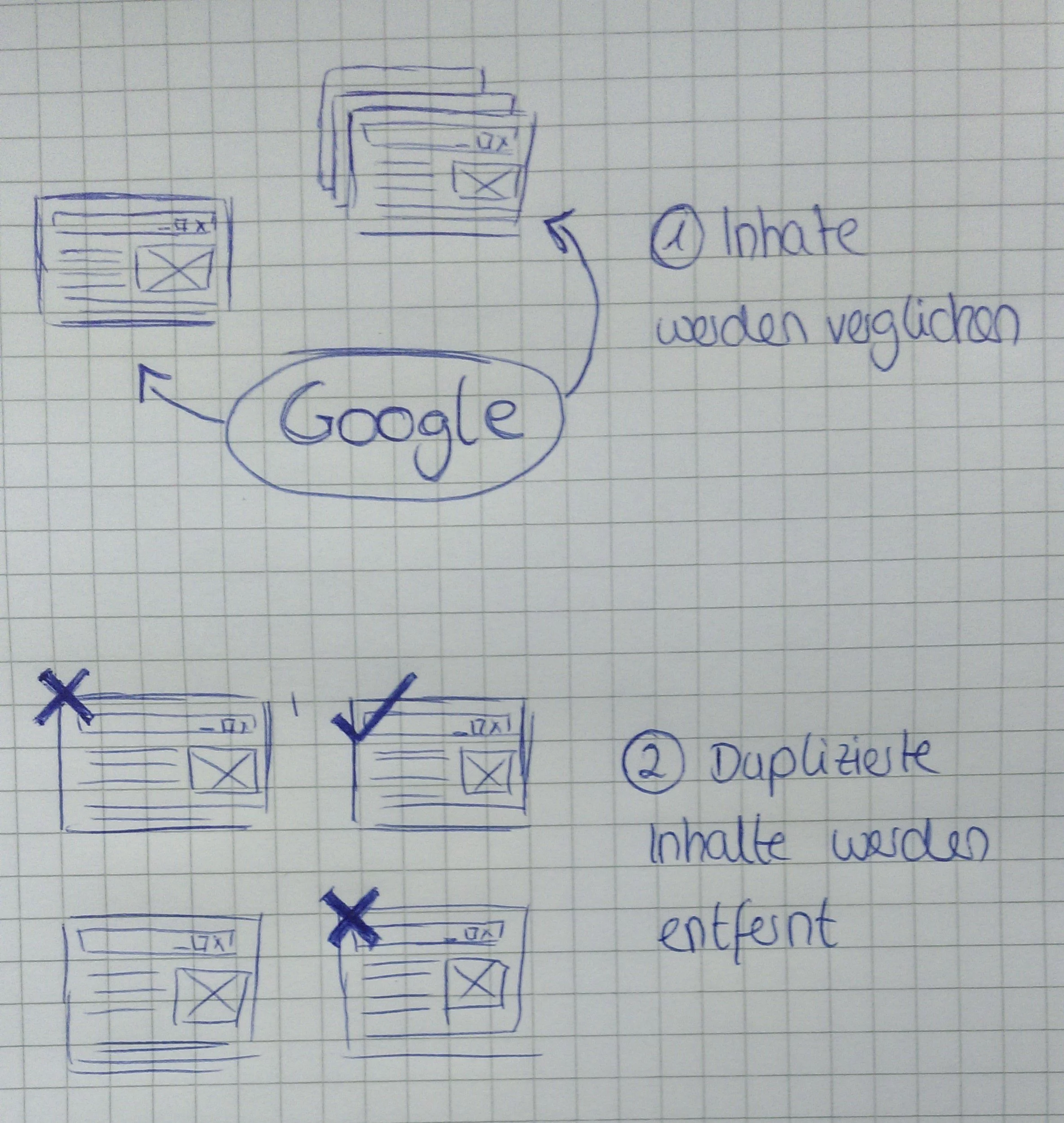
Duplicate Content erkennen
Das Vermeiden von duplizierten Webinhalten ist für SEO von großer Bedeutung, um in den SERPs möglichst hoch gerankt zu werden. Duplicate Content Checker sind Tools, mit denen Webmaster kopierte Inhalte finden. Auch bei der On-Page Optimierung sollte nahezu identischer Content identifiziert und vermieden werden. Als einfache Methode, um händisch doppelte Inhalte zu finden, können Textausschnitte in die Google Suche eingegeben werden. Sollte Duplicate Content vorhanden sein, wird dieser in den Ergebnissen angezeigt.
Vermeidung von identischen Inhalten
Google gibt folgende Tipps für die Vermeidung:
- Im Falle einer Neustrukturierung eine 301-Weiterleitung einrichten
- Auf Konsistenz auch bei internen Links achten (z. B. die gleichzeitige Verwendung von Linkvariationen vermeiden)
- Domain auf oberster Ebene verwenden, um sicherzustellen, dass die richtige Version zur Verfügung gestellt wird (beispielsweise bei landesspezifischen Content)
- Syndizierter Content sollte einen Link zum Ursprungstext enthalten, da Google ansonsten bei der Suchanfrage entscheidet welcher Text im Index erscheint
- Einstellungen in der Search Console über z. B. bevorzugten Hostnamen
- Vermeidung von wiederkehrenden Textbausteinen
- Platzhalterseiten mit Meta-Tag “noindex”, um eine Indexierung von leeren Seiten zu vermeiden
- Unique Content erstellen
Fragen Sie jetzt uns als Content-Marketing Agentur um Rat!