robots.txt
Die robots.txt ist eine Textdatei welche Anweisung an den Robot/Crawler einer Suchmaschine wie Google oder Bing beinhaltet. Der Hauptzweck der robots.txt besteht darin, einer Suchmaschine mitzuteilen, welche Bereiche einer Webseite nicht gecrawlt werden sollen. Es handelt sich entsprechend um eine Art Blacklist bzw. Steuerungsdatei, welche jedoch nicht als bindend anzusehen ist. Eine URL welche nicht im Index ist, existiert aus Sicht einer Suchmaschine nicht im Web. Nicht jeder Crawler hält sich an die Anweisungen welchen in der robots.txt aufgeführt werden. Die bekannten Suchmaschinen halten sich jedoch an die Anweisungen. Im Gegensatz zu dem Ausschluss mittels Meta-Tag, welcher dem Ausschluss von einzelnen Unterseiten dient, beziehen sich die Anweisungen der Textdatei vor allem auf den Ausschluss ganzer Bereiche einer Domain. Einzelne Dateien bzw. URLs sind jedoch auch möglich. Dazu zählen Verzeichnisse ebenso wie URLs welche bestimmte Zeichenketten enthalten.
Weiterhin kann ein Verweis auf eine vorhandene XML-Sitemap angegeben werden, welche einer Suchmaschine eine strukturierte Liste aller URLs einer Domain liefert.
Inhaltsverzeichnis
Aufbau und Speicherort
Das Protokoll welches der robots.txt zugrunde liegt ist ein sogenannter Defacto-Standard. Das heißt, dass „Robots Exclusion Standard Protokoll“ (REP) von 1994 ist kein RFC Standard, wird in der Praxis jedoch behandelt und Betreiber einer Webseite können sich darauf verlassen, dass korrekt aufgebaute Dateien entsprechend korrekt durch die Suchmaschinen behandelt werden. Zwar gibt es wie bereits erwähnt keine Garantie, dass sich alle Robots an die Anweisungen halten, doch in den meisten Fällen ist die Funktion gewährleistet.
Das REP legt fest, dass Suchmaschinen vor Beginn der eigentlichen Indizierung der Webseite zunächst im Hauptverzeichnis der Domain nach einer robots.txt sucht und die darin enthaltenen Anweisungen auswertet. Diese Vorgaben legen zugleich auch den Speicherort fest. Die robots.txt muss im Root-Verzeichnis eines Webservers gespeichert werden und muss vollständig klein geschrieben werden. Wird die Datei Robots.txt benannt wird der Inhalt ignoriert.
Zu beachten ist, dass das Aussperren der Robots jedoch keinen Zugriffsschutz bietet. Ein Webbrowser ignoriert die Datei und jeder Benutzer kann die Inhalte aufrufen. Sollen also Inhalte geschützt werden, so kann z.B. ein oder mehrere Verzeichnisse mittels .htaccess oder anderen Mitteln geschützt werden. Die robots.txt ersetzt keinen Passwortschutz.
Der Aufbau der Datei erfolgt (fast) immer in zweier Blöcken bzw. Zeilen. In der ersten Zeile gibt der Webmaster an, für welchen User-Agent die Anweisung gelten soll (z.B. Googlebot). In der zweiten Zeile wird das Verzeichnis, bzw. der Bereich der ausgeschlossen werden soll, angegeben. Soll ein Bereich unterhalb der ausgeschlossene Ebene dem Robot zugänglich gemacht werden, so muss dieser explizit angegeben werden. Eine Ausnahme bildet hier z.B. die Angabe einer XML-Sitemap, dieser Angabe erfolgt in einer Zeile.
Beispiel für den Aufbau
#Kommentar (einen Kommentar beginnt man mit einer Raute) User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://www.advidera.com/sitemap.xml
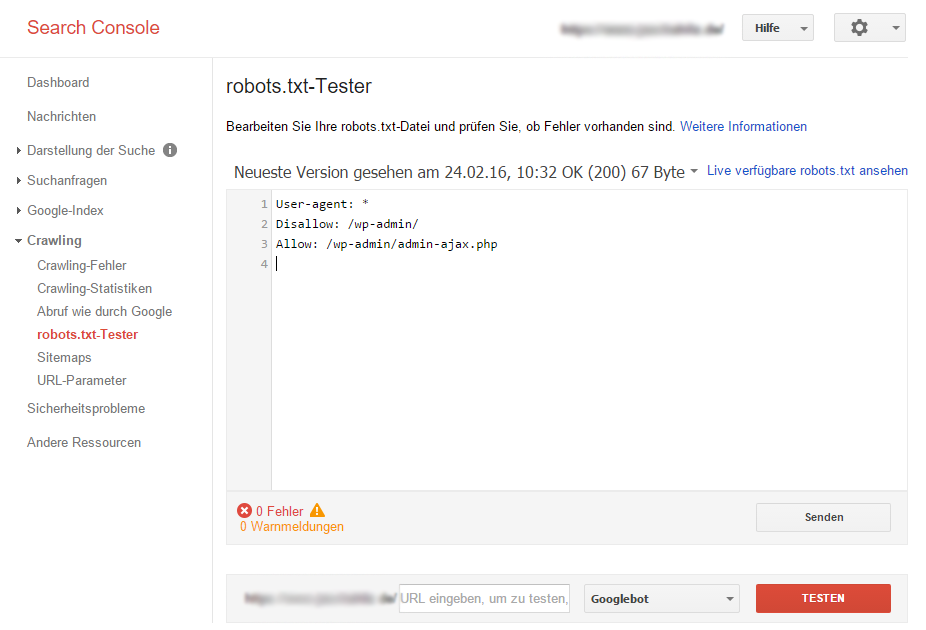
Vor dem Hochladen der robots.txt sollte die Datei unbedingt auf Fehler überprüft werden. Jeder Syntax oder Logik Fehler kann zur vollständigen Unbrauchbarkeit der Funktion und schlimmstenfalls Bereich für Suchmaschinen sperren, welche eigentlich in den Index aufgenommen werden sollten. Eine Möglichkeit zur Überprüfung bietet die Google Search Console. Unter dem Menüpunkt Crawling → robots.txt-Tester kann die Funktion der Datei getestet werden. Auch die Live Version kann dort getestet werden.
Syntax und Beispiele
Nachfolgend ist eine Liste von Kommandos welche mit dem REP in der robots.txt angewiesen werden können.
| Kommando | Bedeutung | Beispiel |
|---|---|---|
| # | Kommentar | # das ist die robotx.txt für www.advidera.com |
| * | Wildcard (für User Agent und URL-Fragmente) | Disallow: /*? |
| $ | Pfadende (z.B. um bestimmte Datei-Typen auszuschließen) | Disallow: /*.pdf$ |
| User-agent: | Robot für den die Anweisung gilt | User-agent: Googlebot |
| Allow: | Erlauben (default Wert) | Allow: /erlaubtes-verzeichnis/ |
| Disallow: | Verbieten | Disallow: /verbotenes-verzeichnis/ |
| Sitemap: | Speicherort der Sitemap(s) | Sitemap: https://www.advidera.de/sitemap.xml |
Alle Suchmaschinen vollständig aussperren.
User-agent: * Disallow: /
Nur den Googlebot aussperren.
User-agent: Googlebot Disallow: /
Nur dem Googlebot den Zugriff erlauben.
User-agent: Googlebot Allow: / User-agent: * (damit werden alle anderen Crawler außer dem Googlebot ausgeschlossen) Disallow: /
Nur Yahoo und Google erlauben.
User-agent: Googlebot User-agent: Slurp Allow: / User-agent: * (damit werden alle anderen Crawler ausgeschlossen) Disallow: /
Ein bestimmtes Verzeichnis für alle Bots sperren.
User-agent: * Disallow: /gesperrtes-verzeichnis/
Parametrisierte URLs von der Indexierung aussperren.
User-agent: * Disallow: /*?
Einzelne URLs von der Indexierung aussperren.
User-agent: * Disallow: /verzeichnis/gesperrte-datei.html
Wildcards in der robots.txt arbeiten
Wildcards sind eine Art regulärer Ausdruck mit deren Hilfe nach bestimmten String/Text Mustern innerhalb der URLs gesucht und gefiltert werden kann. Offiziell unterstützt das REP zwar keinen regulären Ausdrücke, jedoch werden von den großen Suchmaschinen Parameter wie * und $ unterstützt. Wildcards sollten nur zum Ausschluss verwendet werden, da die Crawler den „ganzen Rest“ für gewöhnlich ohne spezielle Anweisungen auslesen.
Wichtig zu wissen: Nicht jeder Robot unterstützen Wildcards, daher sollte man sich nicht zu 100 % darauf verlasen.
Beispiele für die Nutzung von Wildcards
Alle URLs für Bots sperren welche den String „verboten“ enthalten.
User-agent: * Disallow: *verboten
Alle URLs für Bots sperren welche mit den String „.verboten“ enden.
User-agent: * Disallow: *.verboten$
Analog können z.B. URLs ausschließen welche bestimmte Datei-Typen enthalten. So können mittels „Disallow: /*.xls$“ alle Excel Dateien ausgeschlossen werden. Auch PDF oder andere anderen Datei Typen sind möglich.
Liste wichtiger Such-Bots/Agents:
| Suche | User-Agent |
| Google Google-Bildersuche Google-Ads Google-Adsense Yahoo MSN / bing Teoma/Ask Internet Archive Exalead |
Googlebot Googlebot-Image Adsbot-Google MediaPartners-Google Slurp Msnbot / bingbot Teoma ia_archiver Exabot |
Um mehr als einen Bot anzusprechen, muss jeder Robot eine eigene Zeile in der robots.txt erhalten. Eine Auflistung die mittels Kommas o.Ä. getrennt wird funktioniert nicht. Eine Liste (fast) aller bekannten Agents ist unter http://www.user-agents.org/ zu finden. Es gibt jedoch noch weitere Robots wie den Applebot, der dort nicht aufgeführt ist.
Bedeutung der robots.txt für die Suchmaschinenoptimierung (SEO)
Die robots.txt hat für die Suchmaschinenoptimierung eine sehr hohe Bedeutung. Sie ist das zentrale Mittel, um das Verhalten der Robots zu steuern. Anweisungen in der Datei haben unmittelbaren Einfluss darauf ob bestimmte Seite überhaupt in den Index aufgenommen werden können oder nicht. Ohne eine Aufnahme in den Index können jedoch keinerlei Rankings erzielt werden (bis auf wenige Ausnahmen, die bei stark verlinkten URLs vorkommen können). Daher sollte die Datei vor jeder Aktualisierung auf syntaktische und logische Fehler überprüft werden, da eine nicht Enddeckung fatale Folgen für eine Unternehmen haben kann. Lange Zeit unentdeckt geht nicht nur möglicher Traffic verloren, jedwede SEO-Maßnahme greift auch nicht. Einen Einfluss auf das eigentliche Ranking bei einer Suchmaschine besteht jedoch nicht. Dafür sind die Faktoren der Onpage-Optimierung bzw. der Offpage-Optimierung verantwortlich.
Häufige Fragen
Was ist eine robots.txt?
Unter der robots.txt versteht man eine Textdatei, die Anweisungen für Suchmaschinen bezüglich des Crawlings beinhaltet. In ihr sind die Elemente einer Website enthalten, die nicht indexiert werden sollen.
Wie ist eine robots.txt aufgebaut?
Die Datei ist wenig komplex strukturiert und besteht nahezu ausschließlich aus zwei Zeilen. In der oberen Zeile wird der User-Agent angegeben, für den der enthaltene Befehl gilt. Im zweiten Teil wird der Bereich notiert, der von Crawlern nicht erfasst werden soll.
Welche Kommandos können in einer robots.txt enthalten sein?
Zu den gültigen Befehlen in einer robots.txt gehören die Sonderzeichen # (Kommentar), * (Wildcard) und $ (Pfadende) sowie die Begriffe User-agent, Allow, Disallow und Sitemap.
Quellen
- https://de.wikipedia.org/wiki/Robots_Exclusion_Standard
- https://de.onpage.org/wiki/Robots.txt
- http://www.seo-trainee.de/robots-txt-so-wirds-gemacht/
- https://www.mindshape.de/blog/seo/seo-kompakt-alles-was-ein-seo-uber-die-robots-txt-wissen-muss.html
- http://www.suchmaschinen-doktor.de/optimierung/robots-txt.html
- https://wiki.selfhtml.org/wiki/Grundlagen/Robots.txt